برآورد نقطهای: تخمین پارامتر جامعه با یک عدد منفرد از روی نمونه
تعریف برآورد نقطهای و اجزای آن
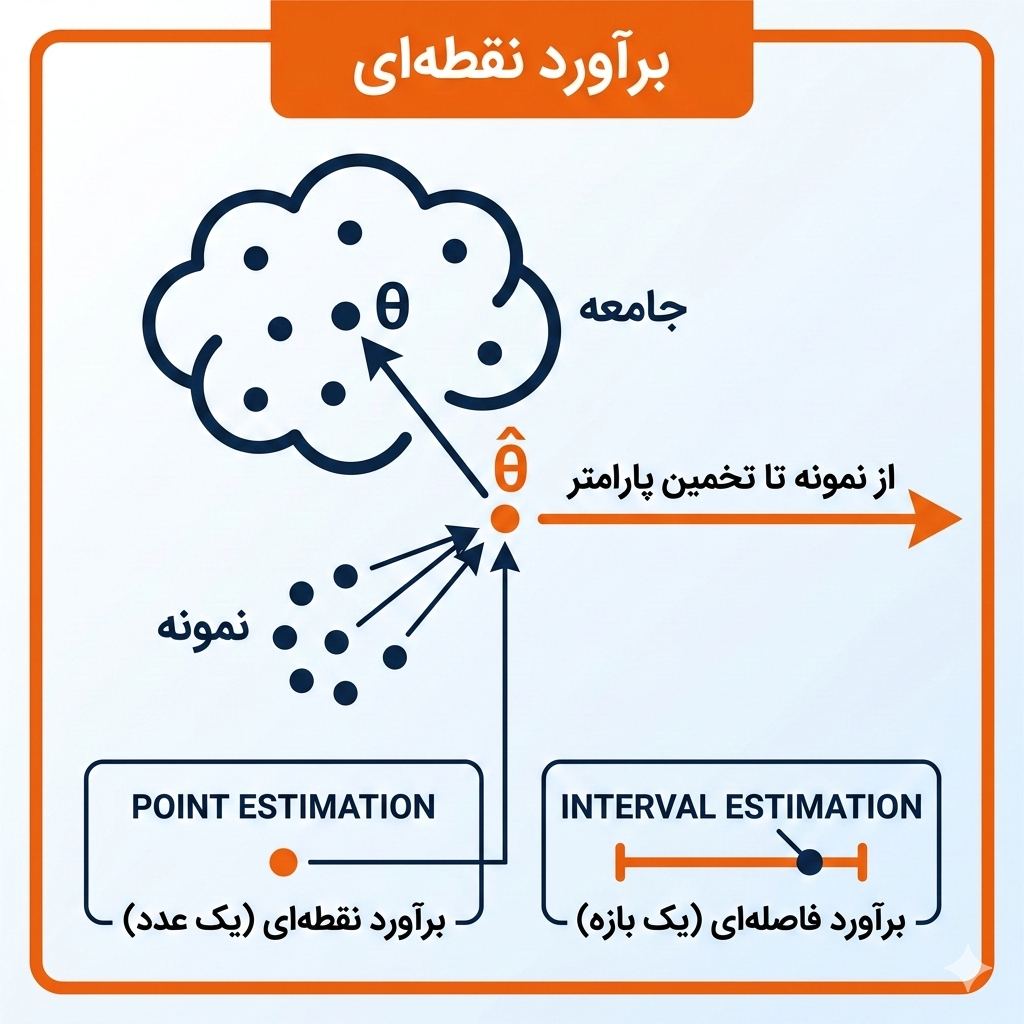
در علم آمار، وقتی میخواهیم درباره یک ویژگی خاص از یک جمعیت بزرگ (جامعه) نظر بدهیم، معمولاً نمیتوانیم همه افراد آن جامعه را بررسی کنیم. به جای آن، از یک نمونه تصادفی استفاده میکنیم. برآورد نقطهای1 یعنی استفاده از یک عدد که از روی نمونه به دست آمده (آماره نمونه) برای تخمین مقدار واقعی در جامعه (پارامتر جامعه).
برای مثال، فرض کنید میخواهیم میانگین قد دانشآموزان یک شهر را بدانیم. به جای اندازهگیری قد همه دانشآموزان (که هزینه و زمان زیادی میبرد)، یک نمونه 100 نفری را انتخاب کرده و میانگین قد آنها را حساب میکنیم. این میانگین، یک برآورد نقطهای از میانگین قد تمام دانشآموزان شهر است.
انواع رایج برآوردگرهای نقطهای
در آمار، برای پارامترهای مختلف جامعه، برآوردگرهای متفاوتی وجود دارد. مهمترین آنها که در دبیرستان با آنها سروکار داریم، برآورد میانگین، واریانس و نسبت هستند. برای درک بهتر، این موارد را در جدول زیر مقایسه میکنیم.
| پارامتر جامعه | برآوردگر نقطهای (آماره نمونه) | نماد ریاضی | مثال عددی |
|---|---|---|---|
| میانگین ($\mu$) | میانگین نمونه ($\bar{x}$) | $\bar{x} = \frac{\sum_{i=1}^{n}x_i}{n}$ | میانگین قد 5 دانشآموز: [150, 160, 155, 165, 170]→160 سانتیمتر |
| واریانس ($\sigma^2$) | واریانس نمونه ($s^2$) | $s^2 = \frac{\sum_{i=1}^{n}(x_i - \bar{x})^2}{n-1}$ | واریانس نمونه قد: 62.5 |
| نسبت ($p$) | نسبت نمونه ($\hat{p}$) | $\hat{p} = \frac{x}{n}$ | در یک نمونه 50 نفری، 30 نفر موافق هستند. نسبت موافق: 0.6 (60%) |
ویژگیهای یک برآوردگر نقطهای خوب
همه برآوردگرها یکسان نیستند. یک برآوردگر خوب باید دارای ویژگیهایی باشد تا بتوان به نتیجه آن اعتماد کرد. مهمترین این ویژگیها عبارتند از:
- نااریبی2 (Unbiasedness): یعنی اگر بارها و بارها نمونهگیری کنیم و هر بار برآوردگر را محاسبه کنیم، میانگین این برآوردگرها با مقدار واقعی پارامتر جامعه برابر باشد. به عبارت ساده، برآوردگر نه به طور سیستماتیک کمتخمین میزند و نه بیشتخمین. برای مثال، میانگین نمونه $\bar{x}$ یک برآوردگر نااریب برای میانگین جامعه $\mu$ است.
- کارایی3 (Efficiency): بین دو برآوردگر نااریب، آنکه واریانس کمتری دارد (یعنی مقادیرش کمتر در اطراف هدف پراکنده است) کاراتر نامیده میشود. برآوردگر کارا، تخمینهای دقیقتری ارائه میدهد.
- سازگاری4 (Consistency): با افزایش حجم نمونه، برآوردگر به مقدار واقعی پارامتر نزدیکتر شود. یعنی هر چه اطلاعات بیشتری داشته باشیم، تخمین ما بهتر میشود.
برای روشنتر شدن مفهوم نااریبی، به این مثال توجه کنید: فرض کنید وزن واقعی یک کیسه برنج 10 کیلوگرم است. اگر با یک ترازوی سالم چند بار آن را وزن کنیم، اعداد 9.8، 10.1، 9.9 و 10.2 را میبینیم. میانگین این اعداد حدود 10 میشود (نااریب). اما اگر ترازو همیشه 0.5 کیلوگرم کمتر نشان دهد، میانگین اعداد حدود 9.5 خواهد شد که یک برآوردگر اریب است.
مثال عینی: تخمین میزان رضایت مشتریان
فرض کنید مدیر یک فروشگاه اینترنتی میخواهد بداند چه درصدی از مشتریانش از خدمات تحویل سریع رضایت کامل دارند. از آنجا که تعداد مشتریان بسیار زیاد است (جامعه)، او یک نمونه تصادفی از 200 مشتری را انتخاب کرده و از آنها نظرخواهی میکند. در این نمونه، 160 نفر اعلام میکنند که کاملاً راضی هستند. بنابراین، برآورد نقطهای نسبت مشتریان راضی در کل جامعه برابر است با $\hat{p} = \frac{160}{200} = 0.8$ یا 80%.
مدیر اکنون میداند که بهترین تخمین او از میزان رضایت کلی، 80% است. البته او میداند که اگر نمونه دیگری انتخاب میکرد، ممکن بود عددی مثل 78% یا 82% به دست آید. به همین دلیل، گام بعدی میتواند محاسبه برآورد فاصلهای برای دیدن محدوده احتمالی این درصد باشد.
تفاوت برآورد نقطهای و برآورد فاصلهای
یکی از سوالات رایج این است که چرا به جای یک عدد، یک بازنده به ما نمیدهید؟ برآورد نقطهای یک عدد منفرد است، در حالی که برآورد فاصلهای5 یک بازه (فاصله) را به عنوان تخمین ارائه میدهد که با یک سطح اطمینان مشخص، پارامتر جامعه در آن قرار دارد. برآورد نقطهای سادهتر است اما اطلاعاتی درباره میزان عدم قطعیت نمیدهد. برآورد فاصلهای اطلاعات بیشتری دارد اما پیچیدهتر است.
| ویژگی | برآورد نقطهای | برآورد فاصلهای |
|---|---|---|
| خروجی | یک عدد منفرد (مثلاً 80%) | یک بازه (مثلاً 75% تا 85%) |
| اطلاع از عدم قطعیت | نمیدهد | میدهد |
| پیچیدگی محاسبه | ساده | نیازمند محاسبه انحراف معیار و سطح اطمینان |
| کاربرد | ارائه یک تخمین سریع و سرراست | تصمیمگیریهای دقیق و علمی |
چالشهای مفهومی
❓ چرا نمیتوانیم صد در صد مطمئن باشیم که برآورد نقطهای ما با مقدار واقعی جامعه برابر است؟
زیرا برآورد نقطهای تنها بر اساس اطلاعات یک نمونه محاسبه میشود، نه کل جامعه. هر نمونهای ممکن است با نمونه دیگر متفاوت باشد و هیچکدام دقیقاً معرف کامل جامعه نیستند. این نوسان نمونهگیری باعث میشود همیشه مقداری خطا وجود داشته باشد.
❓ تفاوت بین یک برآوردگر و یک برآورد چیست؟
برآوردگر (Estimator) یک قاعده یا فرمول است که به ما میگوید چگونه از دادههای نمونه برای تخمین استفاده کنیم (مثلاً میانگین نمونه). اما برآورد (Estimate) مقدار عددی مشخصی است که با اعمال آن قاعده روی یک نمونه خاص به دست میآید (مثلاً 160 سانتیمتر).
❓ آیا امکان دارد یک برآوردگر نااریب باشد اما تخمین ضعیفی بدهد؟
بله. یک برآوردگر نااریب ممکن است واریانس بالایی داشته باشد (کارا نباشد). یعنی اگر نمونههای مختلفی بگیریم، نتایج بسیار پراکندهای به دست میآید که میانگین آنها درست است، اما هر تکرار میتواند خیلی دور از هدف باشد. به همین دلیل، معمولاً به دنبال برآوردگری هستیم که هم نااریب و هم کارا باشد.
پاورقی
1 برآورد نقطهای (Point Estimation): فرآیند استفاده از دادههای نمونه برای محاسبه یک عدد منفرد که به عنوان بهترین تخمین برای یک پارامتر ناشناخته جامعه در نظر گرفته میشود.
2 نااریبی (Unbiasedness): خاصیتی از یک برآوردگر که در آن امید ریاضی برآوردگر با مقدار واقعی پارامتر جامعه برابر است. به عبارت دیگر، برآوردگر به طور متوسط خطایی ندارد.
3 کارایی (Efficiency): ویژگی یک برآوردگر که در مقایسه با سایر برآوردگرها، کمترین واریانس را داشته باشد.
4 سازگاری (Consistency): خاصیتی از یک برآوردگر که با افزایش حجم نمونه، به مقدار واقعی پارامتر جامعه همگرا شود.
5 برآورد فاصلهای (Interval Estimation): روشی برای تخمین یک پارامتر جامعه که یک بازه محتمل برای آن پارامتر به همراه یک سطح اطمینان مشخص ارائه میدهد.
