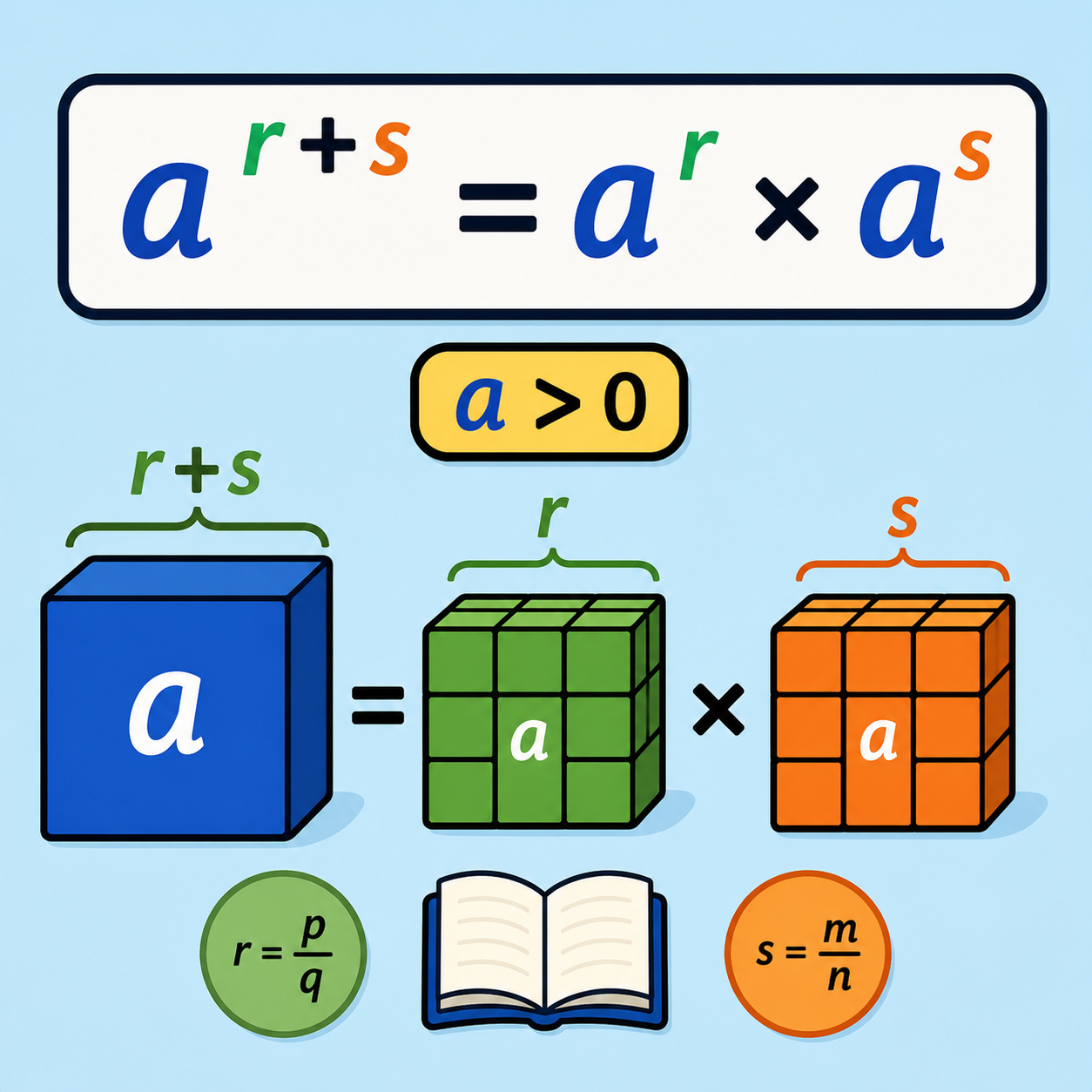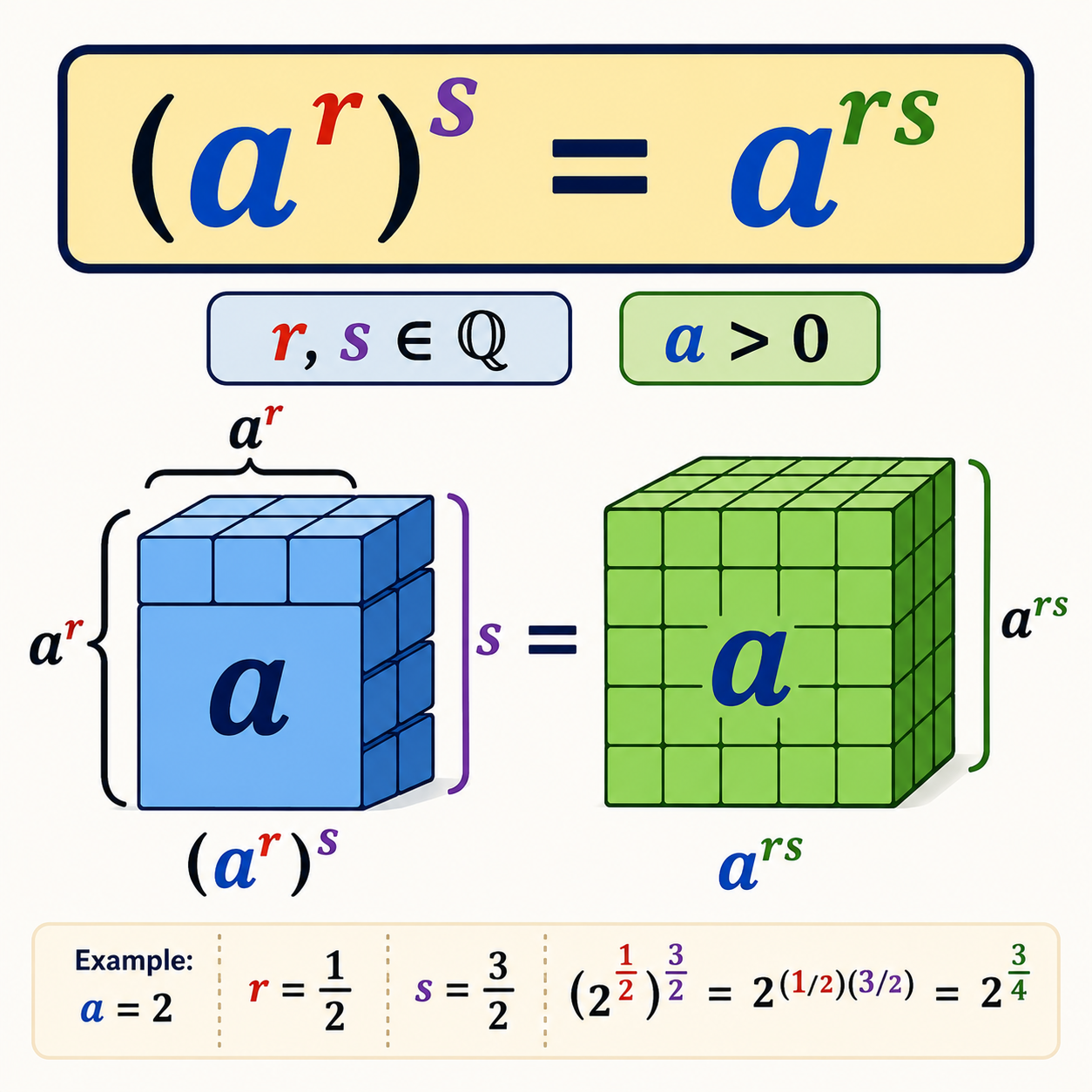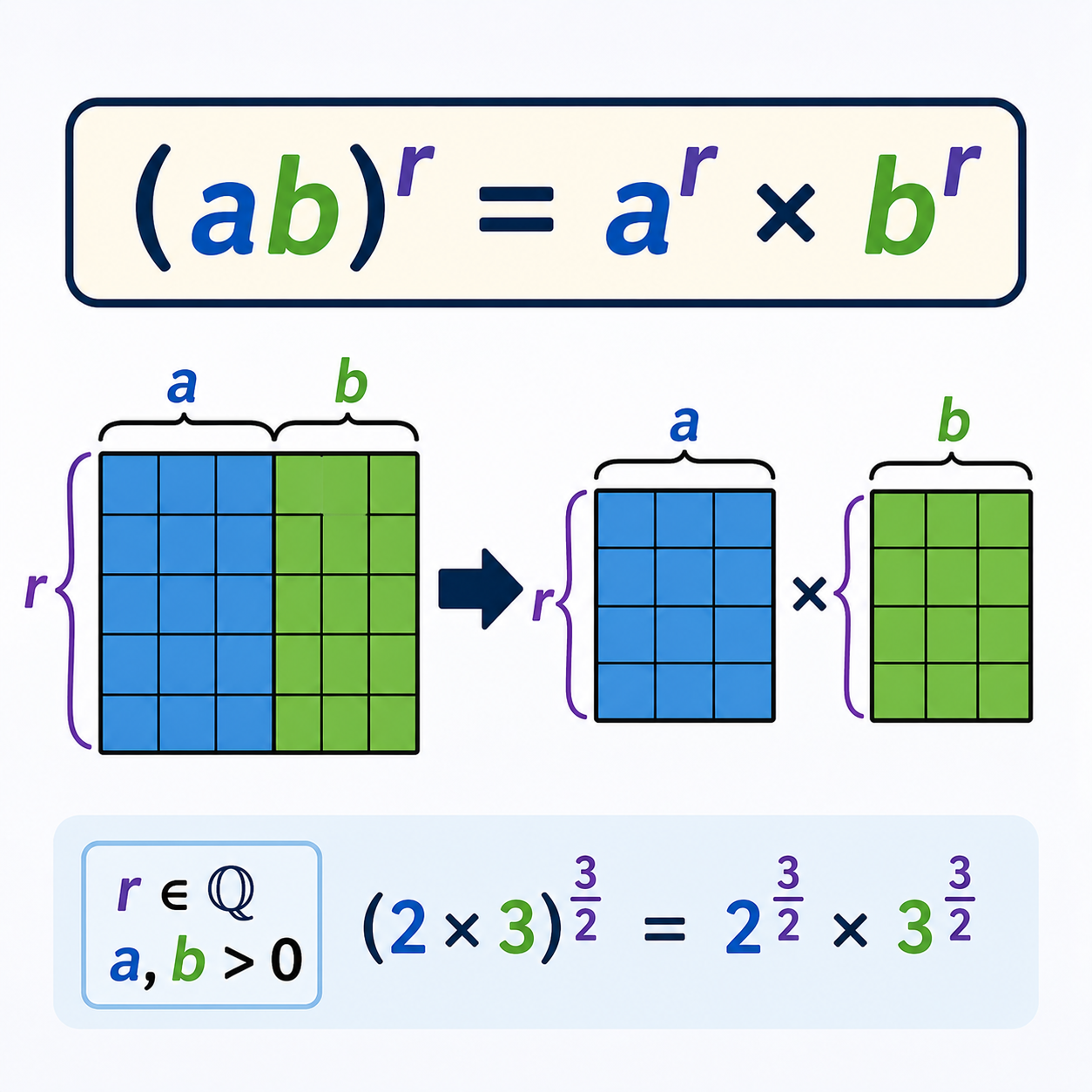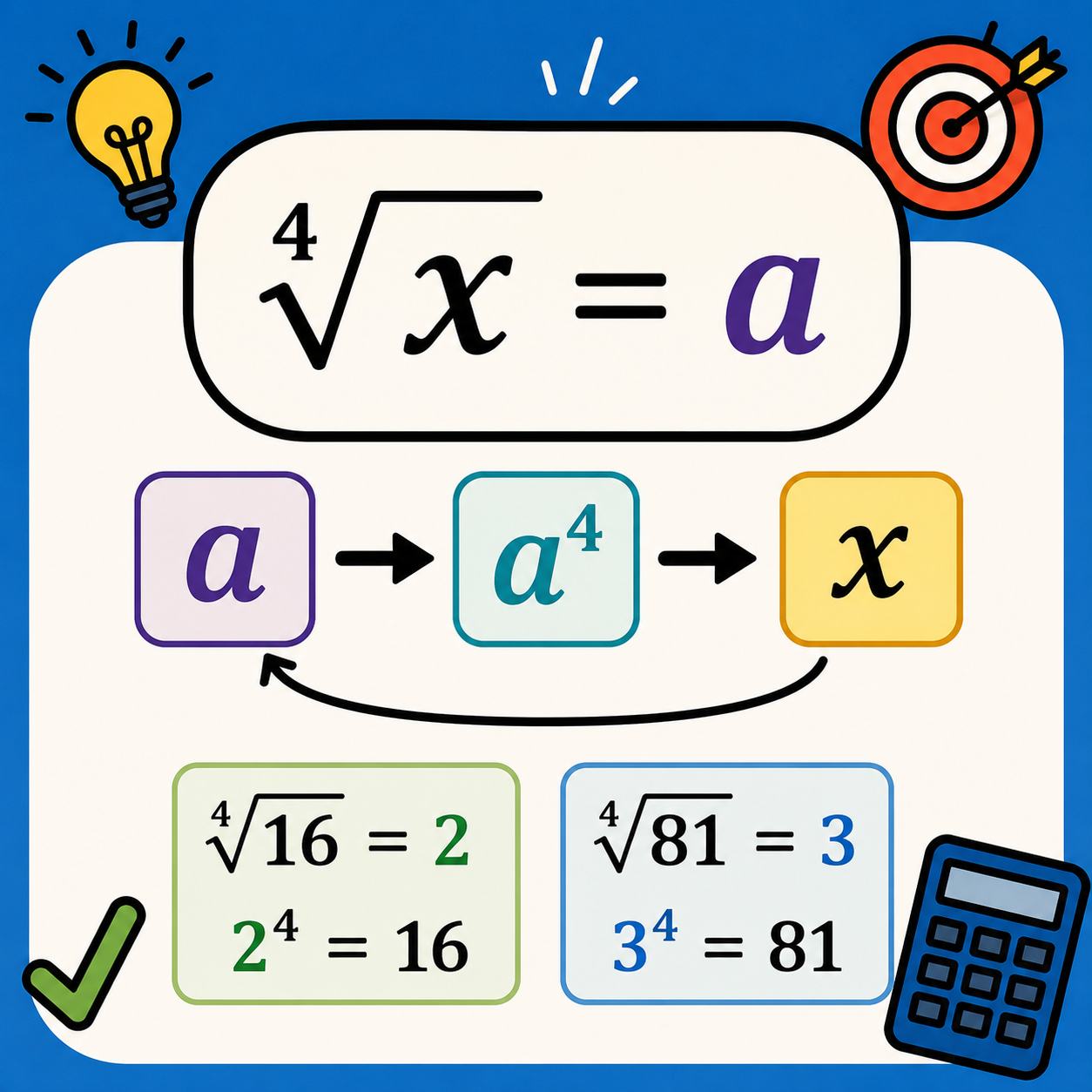
شیء متمایز: تعریف، اهمیت و کاربردها
۱. تعریف بنیادین: متمایز بودن به چه معناست؟
یک شیء زمانی متمایز (Distinct) محسوب میشود که بتوان آن را از سایر اشیاء موجود در یک مجموعه یا گروه تشخیص داد و جدا کرد [۱]. به عبارت دیگر، هر شیء متمایز دارای هویتی منحصربهفرد است که آن را از همهٔ اشیاء دیگر، حتی اگر بسیار شبیه به آنها باشد، متفاوت میسازد [۲]. این ویژگی، هستهٔ اصلی مفهوم هویت (Identity) در بسیاری از حوزههای دانش است.
برای درک بهتر، به دو توپ قرمز رنگ کاملاً یکسان در یک جعبه فکر کنید. اگرچه از نظر رنگ، اندازه و جنس با هم برابر هستند، اما آنها دو شیء متمایز هستند. شما میتوانید یکی از آنها را بردارید و جابهجا کنید، بدون اینکه روی دیگری تأثیری بگذارد. این قابلیت تشخیص و جداسازی، همان معنای تمایز است.
۲. اشیاء متمایز در ریاضیات و علوم کامپیوتر
مفهوم تمایز در ریاضیات، بهویژه در نظریه مجموعهها (Set Theory) نقشی اساسی دارد. یک مجموعه دقیقاً به عنوان «گردآوردهای از اشیاء متمایز» تعریف میشود [۳]. یعنی در یک مجموعه، هیچ عنصر تکراری وجود ندارد. برای مثال، مجموعه {۲، ۱، ۱} معتبر نیست، زیرا عنصر ۱ دو بار تکرار شده است. شکل درست آن {۲، ۱} است که شامل دو عدد متمایز میباشد.
در برنامهنویسی شیءگرا (Object-Oriented Programming)، هر شیء ایجاد شده در حافظه کامپیوتر یک هویت منحصربهفرد دارد. حتی اگر دو شیء دارای دقیقاً خصوصیات یکسانی باشند (مثلاً دو شیء «خودرو» با رنگ و مدل یکسان)، در حافظه متمایز هستند و میتوان به طور جداگانه به آنها ارجاع داد [۴]. این تفاوت در عمل، امکان بهروزرسانی مستقل هر شیء را فراهم میکند.
۳. کاربرد عملی: مسئله شمارش اشیاء متمایز
یکی از مهمترین کاربردهای مفهوم تمایز، در مسئله شمارش تعداد عناصر منحصربهفرد در یک جریان داده (Data Stream) است. فرض کنید میخواهید بدانید در یک وبسایت پربازدید، تاکنون چند کاربر متمایز (Distinct User) وارد شدهاند. ذخیرهسازی نام تمام کاربران و جستجوی تکراری نبودن هر کاربر جدید، حافظهٔ بسیار زیادی مصرف میکند [۵].
برای حل این مشکل، دانشمندان کامپیوتر الگوریتمهای هوشمندانهای مانند الگوریتم CVM ابداع کردهاند. این الگوریتم با استفاده از تصادفیسازی و یک حافظه کوچک، میتواند تخمین بسیار دقیقی از تعداد اشیاء متمایز در یک جریان عظیم داده به دست دهد، بدون اینکه نیاز به ذخیرهسازی تمام آنها باشد [۶].
| مرحله | شرح عملکرد در الگوریتم CVM برای شمارش اشیاء متمایز |
|---|---|
| ۱ | یک حافظهٔ موقت با ظرفیت ثابت (مثلاً ۱۰۰ خانه) در نظر بگیرید. |
| ۲ | با دیدن هر شیء جدید (مثلاً نام کاربر)، اگر در حافظه نبود، با احتمال مشخصی آن را به حافظه اضافه کنید. |
| ۳ | وقتی حافظه پر شد، برای هر شیء در حافظه یک سکه بیندازید. اگر شیر آمد، آن را نگه دارید و اگر خط آمد، حذفش کنید. |
| ۴ | این فرآیند را در مراحل بعدی با کاهش احتمال نگهداری (مثلاً شیر آوردن متوالی) تکرار کنید. |
| ۵ | در پایان، با دانستن تعداد اشیاء موجود در حافظه و احتمال نهایی ماندن هر شیء، تعداد کل اشیاء متمایز تخمین زده میشود. |
۴. متمایز بودن در ترکیبیات و محاسبه احتمالات
در شاخه ترکیبیات (Combinatorics)، تشخیص اینکه اشیاء متمایز هستند یا نه، در محاسبه تعداد حالات ممکن، نقشی کلیدی دارد [۷]. اگر اشیاء متمایز باشند، هر ترتیبدهی متفاوتی از آنها، یک حالت جدید محسوب میشود.
- اگر n شیء متمایز داشته باشیم، تعداد راههای چیدن آنها در یک ردیف (جایگشت) برابر است با !n (فاکتوریل n).
- برای مثال، سه کتاب متفاوت را میتوان به ۳! = ۶ شکل مختلف در قفسه چید. اگر کتابها یکسان بودند، فقط ۱ حالت داشتیم.
$P(n, r) = \frac{n!}{(n-r)!}$
۵. چالشهای مفهومی: پرسش و پاسخ
❓ آیا دو شیء با خصوصیات کاملاً یکسان را میتوان متمایز در نظر گرفت؟
بله. متمایز بودن به هویت شیء وابسته است، نه صرفاً به خصوصیات ظاهری یا ذاتی آن. در دنیای فیزیک، دو برگ کاملاً مشابه از یک درخت، دو شیء متمایز هستند زیرا مکان و لحظهٔ وجودی متفاوتی دارند. در علوم کامپیوتر، دو شیء با مقادیر یکسان در حافظه، همچنان متمایز هستند.
❓ چه ارتباطی بین مفهوم «مجموعه» در ریاضیات و «اشیاء متمایز» وجود دارد؟
ارتباط مستقیم و تعریفکنندهای وجود دارد. یک مجموعه دقیقاً بر اساس اشیاء متمایز تعریف میشود. به زبان ساده، یک مجموعه «کیفی» است که در آن اشیاء تکراری جایی ندارند. اگر شیء تکراری داشته باشیم، مجموعه با حذف تکراریها، به شکل منحصربهفرد خود درمیآید. این اصل، پایه و اساس نظریه مجموعهها است.
❓ چگونه مفهوم تمایز در شمارش دادههای عظیم (Big Data) به کار گرفته میشود؟
در دادههای عظیم، شمارش دقیق اشیاء متمایز (مثلاً تعداد بازدیدکنندگان منحصربهفرد یک وبسایت) با استفاده از روشهای سنتی غیرممکن یا بسیار پرهزینه است. الگوریتمهایی مانند CVM با بهرهگیری از تصادفی و مفهوم احتمال، تخمین میزنند که چند شیء متمایز در جریان داده وجود داشته است. این الگوریتمها با نگهداشتن نمونهای کوچک از دادهها و تحلیل ریاضی آن، پاسخ قابل اعتمادی ارائه میدهند.
پاورقیها
[۱] شیء متمایز (Distinct Object): در فلسفه و علوم، به شیئی گفته میشود که دارای هستی جداگانه و قابل تشخیص از سایر اشیاء است.
[۲] هویت (Identity): مجموعه ویژگیهایی که یک شیء را منحصربهفرد میسازد و آن را از تمام اشیاء دیگر متمایز میکند.
[۳] نظریه مجموعهها (Set Theory): شاخهای از ریاضیات که به مطالعه مجموعهها، یعنی گردآوردههای اشیاء متمایز، میپردازد.
[۴] برنامهنویسی شیءگرا (Object-Oriented Programming - OOP): سبکی از برنامهنویسی که بر پایه «اشیاء» دارای هویت، خصوصیت و رفتار بنا شده است.
[۵] جریان داده (Data Stream): دنبالهای پیوسته و معمولاً سریع از دادهها که پردازش و ذخیرهسازی کامل آنها دشوار است.
[۶] الگوریتم CVM (CVM Algorithm): الگوریتمی تصادفی برای تخمین تعداد عناصر متمایز در یک جریان داده با استفاده از حافظه بسیار کم.
[۷] ترکیبیات (Combinatorics): شاخهای از ریاضیات درباره شمارش، ترکیب و چیدمان اشیاء.